近年來,自然語言處理(NLP)技術發展迅速,尤其是大型語言模型(LLM)的出現,使得人們可以透過自然語言與資料庫進行互動,從而更便捷地獲取數據和資訊。Text2SQL 是一種將自然語言轉換為 SQL 查詢語句的技術,它可以將用戶的自然語言問題轉化為資料庫可以理解和執行的 SQL 語句,從而實現自然語言資料庫查詢。然而,現有的 Text2SQL 方法存在一些局限性,例如只能處理結構化查詢、無法處理需要語義推理或世界知識的複雜問題等。
為了克服這些問題,UCB 和 Stanford 的研究人員提出了一種名為 TAG (Table-Augmented Generation) 的新範式,旨在統一 AI 和資料庫,使其能夠更有效地處理更廣泛的現實查詢。TAG 代表了 AI 與資料庫互動方式的典範轉變,從簡單的自然語言到 SQL 查詢的轉換,轉向更整合和協作的方法。[1] 本文將深入探討 TAG 的原理、演算法和優勢,並與其他 Text-to-SQL 方法進行比較。
TAG 的核心思想
TAG 的核心思想是將 LLM 的推理能力與資料庫的計算能力相結合,以處理需要邏輯推理和知識的複雜查詢。 [2] TAG 不僅僅是將自然語言轉換為 SQL 查詢,而是將 LLM 和資料庫管理系統更緊密地結合在一起,使其能夠協同工作,處理更複雜的任務。 [3] TAG 還可以被視為一個統一的範式,它包含了 Text2SQL 和 RAG,這兩種方法可以被看作是更廣泛的 TAG 架構中的特例。這種統一性使 TAG 能夠處理比以前任何一種方法單獨處理的查詢範圍更廣的查詢。 [1]
TAG 的工作原理
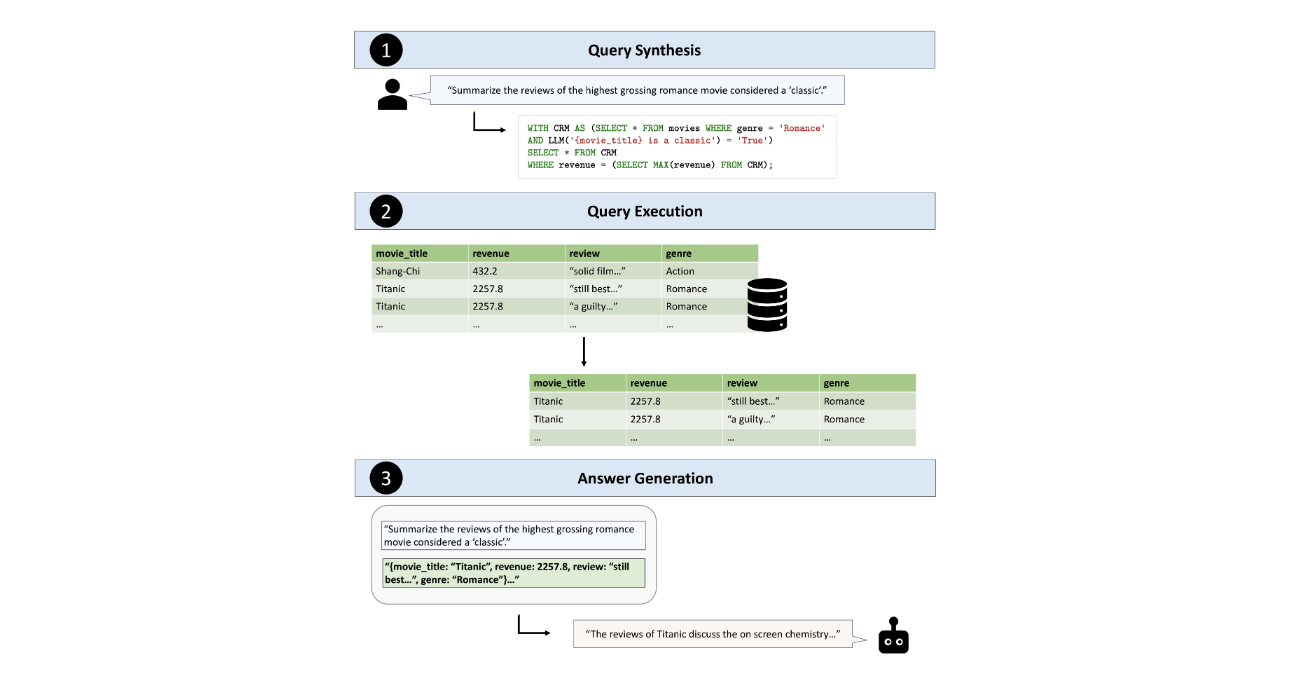
TAG 模型將自然語言問題轉換為資料庫可執行語法的過程可以分為三個關鍵步驟: [3][1]
- 查詢合成: LLM 接收用戶的自然語言請求,並根據資料庫的 schema 資訊生成一個或多個 SQL 查詢語句。
- 查詢執行: 資料庫系統執行生成的 SQL 查詢語句,並返回查詢結果。
- 回應生成: LLM 根據資料庫返回的結果,結合自身的語義推理能力,生成最終的答案。
這三個步驟代表了 LLM 和資料庫之間的協同互動。LLM 利用其語言理解能力生成初始查詢,資料庫執行查詢以檢索相關數據,最後 LLM 利用其推理能力處理檢索到的數據並生成一個全面的答案。
為了評估 TAG 的有效性,研究人員開發了一個專門設計的綜合基準,用於測試模型處理各種複雜查詢的能力。該基準突顯了現有方法的局限性,並強調了在該領域需要進一步研究。 1 研究人員發現,像 Text2SQL 和 RAG 這樣的標準方法只能正確回答基準測試中大約 20% 的查詢,這凸顯了對 TAG 這樣更強大的方法的需求。[1]
與傳統的 Text2SQL 方法相比,TAG 模型引入了 LLM 的語義推理能力,使其能夠處理更複雜的問題,例如:
- 需要領域知識或世界知識的問題: 例如,詢問「哪些客戶評價是正面的?」需要 LLM 對每條評價進行語義分析,才能判斷其情感傾向。[1]
- 需要進行計算或邏輯推理的問題: 例如,詢問「過去一年中收入最高的浪漫電影是哪一部?」需要 LLM 理解「過去一年」是一個相對的概念,並結合資料庫中的數據進行計算。[4]
- 需要對查詢結果進行總結或概括的問題: 例如,詢問「總結一下這部電影的評價」需要 LLM 對資料庫返回的評價文字進行分析和總結。[4]
TAG 的優勢
相比於 Text2SQL 和 RAG 等方法,TAG 具有以下優勢:
- 更強的泛化能力: TAG 可以處理更廣泛的自然語言查詢,包括需要語義推理、世界知識和邏輯計算的複雜問題。 [1] TAG 基準測試包括一組不同的查詢,例如需要對多行進行邏輯推理、數據聚合以及整合世界知識的查詢,這證明了 TAG 能夠處理更廣泛的現實場景。
- 更高的準確性: TAG 結合了 LLM 的推理能力和資料庫的計算能力,可以更準確地理解用戶的查詢意圖,並生成更準確的答案。
- 更高的效率: TAG 有可能透過……來提高查詢效率。
- 更好的可解釋性: TAG 模型的三個步驟清晰明確,使得查詢過程更加透明,易於理解。
TAG 的局限性
儘管 TAG 模型具有很大的潛力,但它也並非沒有局限性。
- 對 LLM 的依賴性: TAG 模型的效能嚴重依賴於 LLM 的推理能力。如果 LLM 的推理能力不足,則 TAG 模型的效能也會受到影響。
- 對資料庫 schema 資訊的依賴性: TAG 模型需要獲取資料庫的 schema 資訊才能生成 SQL 查詢語句。如果資料庫的 schema 資訊不完整或不準確,則 TAG 模型的效能也會受到影響。
- 缺乏公開的模型架構和實驗結果: 目前關於 TAG 模型的論文 [1][2][5] 沒有提供詳細的模型架構和實驗結果。 缺乏詳細資訊使得其他研究人員難以復現結果或在 TAG 模型的基礎上進行構建。此外,它還阻礙了對模型內部工作原理及其效能特徵的全面理解。
TAG 與其他 Text-to-SQL 方法的比較
| 方法 | 查詢類型 | 推理能力 | 數據處理 |
|---|---|---|---|
| Text2SQL | 可以將簡單的自然語言查詢轉換為 SQL 語句,例如「查找所有年齡大於 25 歲的員工」。 | 只能處理結構化查詢,無法處理需要語義推理或世界知識的複雜問題,例如「哪些產品在年輕人中最受歡迎?」 | 主要處理結構化數據,難以處理非結構化數據,例如文字評論。 |
| RAG | 可以處理需要從資料庫中檢索少量數據的查詢,例如「查找 John Smith 的地址」。 | 只能處理簡單的查詢,無法處理需要複雜邏輯推理或計算的問題,例如「比較過去五年中每個季度的銷售額增長」。 | 通常局限於點查找或對資料庫中少量數據的檢索。 |
| TAG | 可以處理更廣泛的自然語言查詢,包括需要語義推理、世界知識和邏輯計算的複雜問題,例如「總結過去一年中收入最高的浪漫電影的評論」。 | 能夠進行複雜的推理,例如理解相對時間範圍(「去年」)、進行情感分析和總結文字。 | 可以處理結構化和非結構化數據,並將 LLM 的推理能力應用於檢索到的數據。 |
TAG 的未來發展方向
TAG 模型作為一種新興的技術,未來還有很大的發展空間。以下是一些可能的發展方向:
- 提高 LLM 的推理能力: 研究人員可以探索如何提高 LLM 在資料庫查詢方面的推理能力,例如透過預訓練 LLM 或使用特定領域的知識圖譜來增強 LLM 的知識。
- 降低對資料庫 schema 資訊的依賴性: 研究人員可以探索如何使 TAG 模型能夠在沒有完整 schema 資訊的情況下進行查詢,例如透過使用 schema 匹配技術或自動 schema 推理技術。
- 開發更有效的查詢優化策略: 研究人員可以探索如何優化 TAG 模型生成的 SQL 查詢語句,以提高查詢效率。
- 構建更全面的評估基準: 研究人員可以構建更全面的評估基準,以更全面地評估 TAG 模型的效能。
總結
由 UCB 和 Stanford 的研究人員提出的 TAG 模型是一種很有前景的自然語言資料庫查詢技術,它結合了 LLM 的推理能力和資料庫的計算能力,可以更有效地處理更廣泛的現實查詢。 [2][1] 雖然 TAG 模型還存在一些局限性,但隨著技術的不斷發展,相信 TAG 模型會在未來得到更廣泛的應用。TAG 不僅提高了查詢的準確性和效率,還為用戶提供了更直觀、更強大的數據分析工具。隨著 LLM 和資料庫技術的不斷發展,TAG 有可能徹底改變我們與數據互動的方式,並為更複雜、更智慧的查詢鋪平道路。
參考資料
[1] Text2SQL is Not Enough: Unifying AI and Databases with TAG – arXiv, accessed January 18, 2025, https://arxiv.org/pdf/2408.14717
[2]Text2SQL is Not Enough: Unifying AI and Databases with TAG, accessed January 18, 2025, https://powerdrill.ai/discover/discover-Text2SQL-is-Not-cm0eccgen5bvg015xl2m4iuve
[3]Text2SQL is not enough? – Medium, accessed January 18, 2025, https://medium.com/@cafecompequi/text2sql-is-not-enough-ade00f33b0f9
[4]TAG vs Text2SQL. To understand how TAG (Table-Augmented… | by Vishal Mysore | Medium, accessed January 18, 2025, https://medium.com/@visrow/tag-vs-text2sql-96542742e401
[5]Text2SQL is Not Enough: Unifying AI and Databases with TAG | AI Research Paper Details, accessed January 18, 2025, https://www.aimodels.fyi/papers/arxiv/text2sql-is-not-enough-unifying-ai-databases
[6]Large language model, accessed January 21, 2025, https://en.wikipedia.org/wiki/Large_language_model